
Fundamentals of Border Gateway Protocol (BGP) - Part 5
May 21, 2019
This post is the 5th in a series of Border Gateway Protocol (BGP) posts. If you missed any of the first four, here are the links:
- Part #1: BGP Overview, Messages Types, and Neighbor States
- Part #2: BGP Path Selection
- Part #3: BGP Peering and Authentication
- Part #4: Advertising NLRI and BGP Routing Policies
In this post, we're going to take a look at BGP scalability mechanisms and related concepts.
BGP Scalability Mechanisms
Just as IP address depletion has been a concern with the Internet, so has the depletion of available autonomous system numbers. To help solve this, the engineers turned to a familiar solution. They marked an AS number range as private-use only. This permits you to experiment with AS construction and policy in a lab (for example) and use AS numbers that are guaranteed not to conflict with Internet-based systems.
Remember, the AS number is a 16-bit number permitting up to 65,536 AS numbers. The private space is marked as 64512-65535.
Another solution to the shortage has been to expand the naming address space. A larger space (32-bit number) has been approved.
For the longest time with Border Gateway Protocol peer groups were considered an absolute must from a scalability perspective. We would configure peer groups for the benefit that it would give us with much smaller configuration files. And we also configured peer groups for performance improvements.
The performance benefits have been done away with much improved mechanisms that we can use. With this said, many organizations still use them as they are so easily understood and in use for configuration shortening.
BGP peer groups arose to solve the ridiculous amount of redundancy in BGP configurations. Consider the simple (and very small) Example 1. Even this simple example still communicates the amount of redundant configuration.

Example 1: A Typical BGP Configuration without Peer Groups
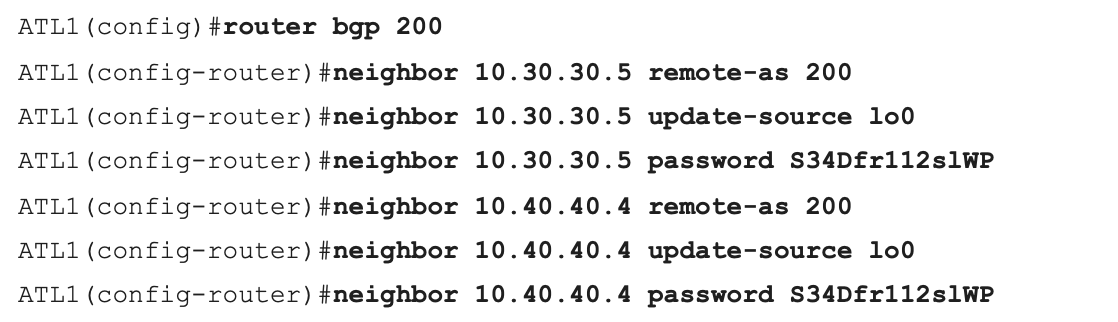
Clearly its all of these configuration commands per neighbor. And many of your neighbors are going to share the same characteristics. It makes sense to group their configurations in a peer group type of configuration. Example 2 shows how you can configure and use a BGP peer group.
Example 2: BGP Peer Groups

Keep in mind that if you have specific configurations for a specific neighbor, you can still enter them in the configuration and they will apply in addition to the peer group configurations.
The other thing about peer groups and why there were so frequently used is they had performance enhancements as well. As a matter of fact, that was the very first initial reason for their creation. It would help with the efficiency of BGP's operations to do peer groups for neighbors instead of individual neighbor configurations.
A more modern (and more effective) approach is to use session templates to shorten configurations. And from a performance enhancement perspective, we now have (as of iOS 12 and later) dynamic update groups. The provide performance enhancements without you needing to configure anything as far as peer groups or templates are concerned.
When you think about a peer group, you realize it's like a template for your settings. And it's going to enable you to utilize session parameters and also policy parameters. Well, the new and improved methodology separates these functionalities into session templates and policy templates.
Thanks to session templates and policy templates, we configure settings required for a session to be properly established and we place those settings in session template. Those that involve policy actions, we place that in a policy template.
One of the great things about using these session or policy templates or both is that they follow an inheritance model. You can have a session template that does certain things with a session. Then you can set up a direct inheritance so that when you create another one it incorporates the things in the one you created previously. This inheritance model is going to give us more flexibility and we can create some really nice scalable designs for BGP implementations.
You can use templates or you can use peer groups, but they're going to be a mutually exclusive choice. So decide on your approach in advance. You're going with the legacy peer group approach or are you going with the session and policy template approach, and then you're going to make that choice and stick with it on the device, because you cannot use both approaches simultaneously.
Now, you really would guess that the configuration would be pretty straightforward for session templates, and it is. Remember, first of all, we are doing here anything that would be relevant to the session. So if we want to set timers, obviously, we need to set the remote-as, that would be something that's considered a session parameter.
Maybe we're doing update source. We're doing eBGP multihop. All this stuff is relevant to the session, and that's what we would have in the session template. Notice we begin by creating the template. So I'd say template peer-session, and then I would give it a name. And then inside of that template configuration mode we could do inheritance, so we could inherit settings from another peer session. We could set our remote-as and/or update source. And then when we're all done, we use this command exit-peer-session in order to get out of the configuration mode for that session. Example 3 shows the configuration of session template.
Example 3: BGP Session Templates

It is a simple matter of configuring a neighbor with the neighbor statement and using inherit peer-session and then giving the name of the peer session that we created for our session template, and that's going to give that neighborship those session settings.
Remember, if you wanted to do some additional configuration of the neighbor, you certainly could just by giving the neighbor, the IP address, and then whatever settings outside of the peer session template that you want to give to that neighbor. So that you still have that same flexibility that we saw with peer groups, where you can still configure individual settings for that specific neighbor outside of the template approach for that neighborship.
You might think that policy templates would be of a similar construction and usage to session templates, and you would be right. Remember, if your session templates are where we're going to configure the parameters that would relate to a BGP session, of course, policy templates are going to be where we store settings that are going to be applying to policy.
Example 4 shows the configuration and usage of a BGP policy template.
Example 4: BGP Policy Templates

Yes, all of these settings that we discussed when we were discussing policy manipulations, those are going to be what we would do inside of a policy template. Now, one key differentiator between our policy template and our session template, though, is the fact that inheritance is going to be even more flexible here.
For instance, we can go up to seven different templates that we can directly inherit policy from. This gives us even more powerful inheritance capabilities with the policy templates when compared to the session templates.
Once again, if we want to do independent individual settings for policy to a specific neighbor, we can do that by adding the appropriate neighbor commands.
Thanks to loop prevention and the IBGP split-horizon rule, among other factors, we know that we need to come up with some scalability solutions for IBGP peerings. One of those solutions is route reflectors.
Examine the topology shown in Figure 1, notice R3 is to be configured as a router reflector.
Figure 1: A Sample Route Reflector Topology

The configuration of route reflection is amazingly simple as it is all handled on the router reflector itself (R3). The clients that we're going to have, the R4, R5, and R6 route reflector clients, they're completely unaware of the configuration and are configured for IBGP peerings with R3 as normal. Example 5 shows an example of a router reflector configuration. Note this is through the simple specification of a route reflector client.
Example 5: BGP Route Reflection

The route reflector automatically creates a cluster ID value for the cluster, and that device and these clients are going to be part of what we call a router reflector cluster. Cisco recommends that you permit the automatic assignment of the cluster ID to identify the client. This is a 32-bit identifier that BGP pulls from the route reflector.
The magic of route reflection is in how the rules of IBGP change. For example, if an update comes in from a route reflector client (let’s say R4), then the R3 device “reflects” this update to its other clients (R5 and R6) as well as its non-clients (R1 and R2). All of this updating occurs even though are configuration for IBGP is well short of a full mesh of peerings that would ordinarily be required.
Now what about if the update comes in from a non-route reflector client (R1)? The route reflector will send that update to all of its route reflector clients (R4, R5, and R6) . But then R3 is going to follow the rules of IBGP, and in this case, it will not send an update via IBGP to the other non-route reflector client (R2).
In order to solve this issue, you would need to create a peering from R1 to the R2 device using IBGP. Or, of course, you could add R2 as a route reflector client of R3.
There is another way that we could attack the issue with IBGP scalability, and this is to manipulate the EBGP behavior. We do this with confederations. You just don't see confederations used as much as route reflection, and the reason is they are going to add quite a bit of complexity to your topology, and they can make troubleshooting more challenging. Figure 2 shows an example confederation topology.
Figure 2: A Sample Confederation Topology

We've got our AS 100 here. And what we do when we confederate is we go in and we make little sub autonomous systems inside of our main autonomous system. We would number these with, yes, you guessed it, private-use-only autonomous system numbers.
What we have is we are manipulating the EBGP behavior, because we are going to have confederation EBGP peerings that we can then configure between the appropriate devices that we want to use in these sub autonomous systems. As you might guess, they're not going to follow the same rules that our standard EBGP peerings would follow. Another important point is that this whole thing, to the outside non-confederated world, just looks like AS 100.
Inside, we see the actual AS sets that are inside there, and the confederated EBGP relationships between them. Other than eliminating the IBGP split horizon concern, what happens with the confederation EBGP peerings that make them different? Next hop behaviors have to change. The next hop does not change as we're going from one of these little confederations inside our AS to another confederation. Something else that happens is the local preference is going to be maintained between these different entities that we created for scalability. Also, the MED is going to be passed between those entities.
Newly added attributes will serve to ensure there is not a loop due to the confederation. The AS_confed_sequence attribute, and the AS_confed_set are used as loop prevention mechanisms.
Example 6 shows a sample partial BGP confederation configuration.
Example 6: A Sample Partial BGP Confederation Configuration

You will often discover that you need to apply common policies to a large group of prefixes. This is made easy if you flag prefixes with a special attribute value called a community. Note that by themselves, community attributes do nothing to the prefixes other than to affix an identifier value. These are 32-bit values (by default) that we can name to provide extra meaning.
You can configure community values so that they are meaningful to your AS only, or meaningful to a set of ASes. You can also have a prefix that carries multiple community attribute values. It is also simple to add, change, or remove community values as needed inside your BGP topology.
Community attributes can be represented in several formats. The older format is as follows:
- Decimal - 0 to 4294967200
- Hexadecimal – 0x0 to 0xffffffa0
The newer format is to use:
- AA:NN
AA is a 16 bit number that represents your AS number, followed by a 16 bit number that you would use for significance in your own AS for policy. So you might have 100:101 for AS 100 and an internal policy you want applied to the prefixes with this community value that you have numbered 101.
There are also well-known community values. These are:
- No-export – prefixes are not advertised outside of the AS; you can set this value as you send a prefix into a neighbor AS in order to cause that neighbor AS to not advertise the prefix beyond its AS boundary
- Local-AS – prefixes with this community attribute are never advertised beyond the local AS
- No-advertise – prefixes with this community attribute are not advertised to any device
These well-known community attributes are simply identified by their reserved names.
There are also extended communities that you can use. These offer 64-bits for the identification of communities! Often times, these bits are set for that you have a TYPE:VALUE configuration. An extended community setting might look like this:
65535:4294967295
As you might guess, we set (and act) on community values using route maps. Example 7 shows an example. Note that this example also makes use of a prefix list. These are often used in BGP for the flexible identification of many prefixes. They are much more flexible than access lists for this purpose. You specify the bits that must match with a flexible prefix notation, and then you can specify a flexible length of the subnet mask that accompanies the prefixes.
Example 7: Setting Community Values in BGP

Note: It is very easy to set communities and then forget to send them. Do not forget the send-community property as you see in Example 7.
That's going to wrap up Part 5 of our BGP series. Coming up in Part 6, we'll take a look at how we can work with BGP in IPv6. Take good care.
